A fully offline, in-browser vector database for real-time RAG retrieval using SQLite WASM and client-side embeddings.
https://github.com/davidbmar/browser-RAG-retrieval-realtime-night-index-SQLLiteWASM-and-sqllite-vec-portal-vector-db-with-filters · public · shipped
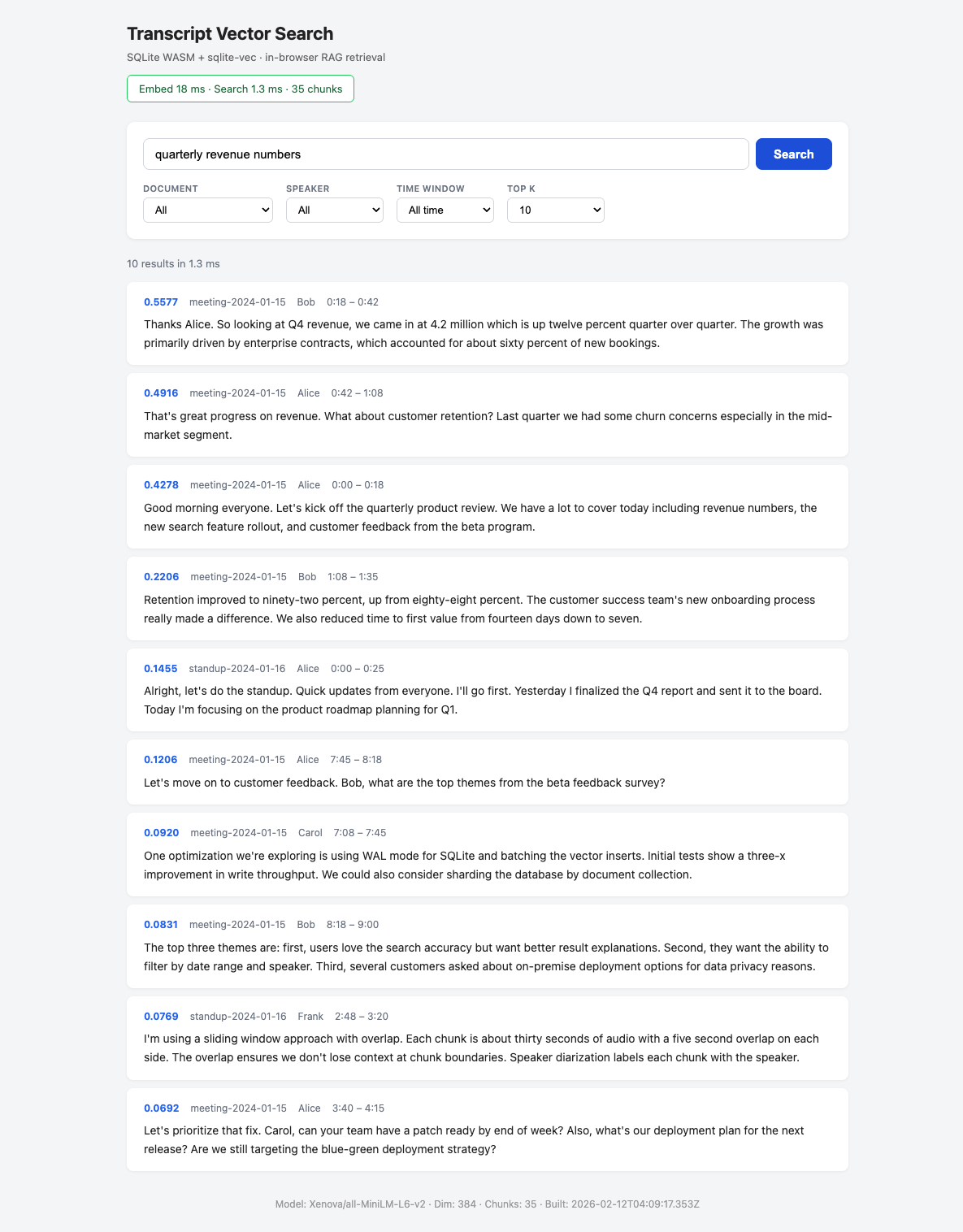
This project implements a client-side Retrieval-Augmented Generation (RAG) system that runs entirely in the browser. It uses a pre-built SQLite database containing transcript chunks and their 384-dimensional vector embeddings. The browser loads this database via sql.js (WASM), caches it in IndexedDB, and performs semantic search using Transformers.js for query embedding generation and JavaScript-based dot-product calculations for similarity scoring. It supports metadata filtering by document ID, speaker, and timestamps without requiring external APIs at query time.
git clone https://github.com/davidbmar/browser-RAG-retrieval-realtime-night-index-SQLLiteWASM-and-sqllite-vec-portal-vector-db-with-filters cd browser-RAG-retrieval-realtime-night-index-SQLLiteWASM-and-sqllite-vec-portal-vector-db-with-filters cd indexer && npm install && cd .. cd web-app && npm install && cd .. ./build_db --input ./data --out ./web-app/public/data/transcripts.db cd web-app npm run dev
flowchart TD
subgraph Offline_Indexer["Offline Indexer (Node.js)"]
JSONL["JSONL Transcripts"] --> Read["Read Chunks"]
Read --> Embed["Generate Embeddings\n(@xenova/transformers)"]
Embed --> DB["Build SQLite DB\n(better-sqlite3 + sqlite-vec)"]
end
subgraph Browser_Client["Browser Client (Vite + TS)"]
Static["Static Assets"] --> Load["Load sql.js WASM"]
Load --> Fetch["Fetch transcripts.db"]
Fetch --> Cache["Cache in IndexedDB"]
Cache --> Open["Open SQLite in Memory"]
User["User Query"] --> QEmbed["Embed Query\n(Transformers.js)"]
QEmbed --> Search["Vector Search\n(JS Dot Product)"]
Open --> Filter["SQL Metadata Filter"]
Filter --> Search
Search --> Results["Display Results"]
end
DB -->|Deploy| Static
The system consists of two main parts: a Node.js indexer and a Vite-based web application. The indexer reads JSONL transcript files, generates embeddings using @xenova/transformers, and writes them into a single SQLite file using better-sqlite3 and sqlite-vec. The web app uses sql.js to load this SQLite file in the browser, caches it in IndexedDB for offline use, and uses Transformers.js (WebGPU/WASM) to embed user queries. Search is performed by loading all embeddings into memory as Float32Arrays and computing cosine similarity in JavaScript, combined with SQL WHERE clauses for metadata filtering.
sequenceDiagram
participant U as User
participant App as Web App
participant IDB as IndexedDB
participant SQL as sql.js (WASM)
participant Model as Transformers.js
Note over App, IDB: Initialization Phase
App->>IDB: Check for cached transcripts.db
alt Not Cached
App->>App: Fetch transcripts.db from server
App->>IDB: Store transcripts.db
else Cached
IDB-->>App: Return cached ArrayBuffer
end
App->>SQL: Open Database from ArrayBuffer
App->>Model: Initialize Embedding Model
Model-->>App: Model Ready
Note over U, Model: Search Phase
U->>App: Enter Search Query + Filters
App->>Model: Embed Query Text
Model-->>App: Return Query Vector (Float32Array)
App->>SQL: Execute SELECT with Metadata Filters
SQL-->>App: Return Filtered Rows (IDs + Embedding Blobs)
App->>App: Compute Cosine Similarity (JS)
App-->>U: Display Ranked Results
Use this pattern for privacy-focused applications requiring semantic search over static datasets (e.g., meeting transcripts, documentation) where server-side inference is undesirable or too costly. It is ideal for demos, internal tools, or edge-case deployments where network latency or connectivity is a constraint. The architecture separates the heavy lifting of index creation (nightly/offline) from the lightweight, responsive query execution (real-time/browser).