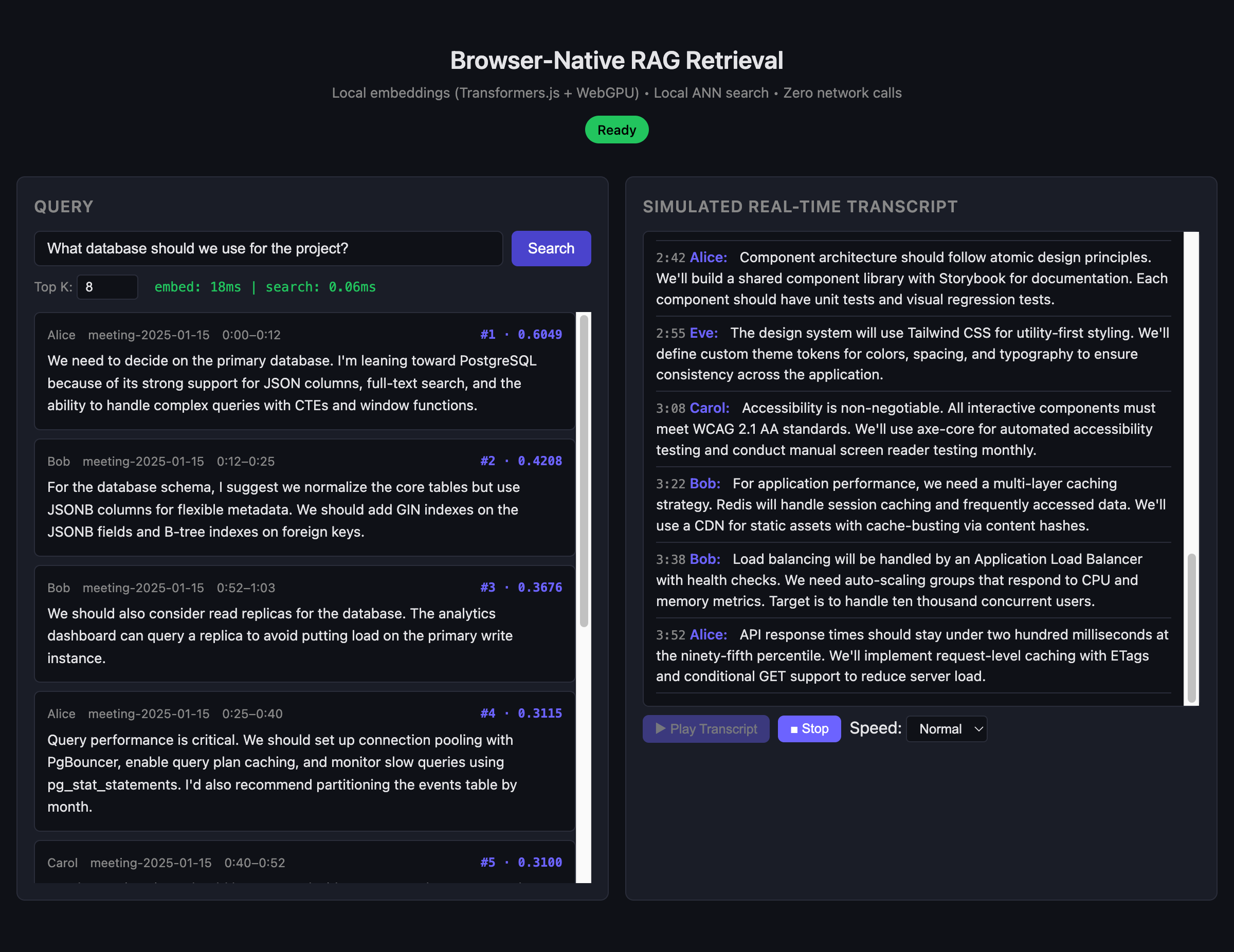
A fully local, WebGPU-accelerated RAG retrieval system that runs embedding and vector search entirely in the browser with zero network calls at query time.
https://github.com/davidbmar/browser-RAG-retrieval-realtime-night-index-transformersjs-webgpu-web-app-vite-typescript · public · shipped
This project implements a production-shaped prototype for real-time transcription apps where the retrieval pipeline (embedding generation and vector search) executes locally. It consists of an offline Node.js indexer that builds HNSW artifacts from JSONL transcripts and a Vite-based web application that loads these artifacts into IndexedDB. The browser runtime uses Transformers.js with WebGPU acceleration to compute query embeddings and performs cosine similarity search within a Web Worker, ensuring the main thread remains responsive.
git clone https://github.com/davidbmar/browser-RAG-retrieval-realtime-night-index-transformersjs-webgpu-web-app-vite-typescript.git cd browser-RAG-retrieval-realtime-night-index-transformersjs-webgpu-web-app-vite-typescript cd indexer-node && npm install cd ../web-app && npm install cd .. cd indexer-node npm run build-index -- --input ../data --out ../artifacts cd ../web-app mkdir -p public/artifacts cp ../artifacts/* public/artifacts/ npm run dev
flowchart TD
subgraph Offline_Indexing["Offline Indexing (Node.js)"]
JSONL["JSONL Chunks"] --> Validate["Validate & Normalize"]
Validate --> Embed["Embed (Transformers.js)"]
Embed --> HNSW["Build HNSW Index (hnswlib-node)"]
HNSW --> Artifacts["Export Artifacts\n(config, metadata, embeddings.bin, hnsw.index)"]
end
subgraph Browser_Runtime["Browser Runtime (Vite + TS)"]
MainThread["Main Thread: UI & Transcript"]
Worker["Web Worker"]
Artifacts -->|Load & Cache| IndexedDB[("IndexedDB")]
IndexedDB -->|Fetch| Worker
MainThread -->|Query Text| Worker
Worker -->|Load Model| TransformersJS["Transformers.js\n(WebGPU/WASM)"]
TransformersJS -->|Query Embedding| Search["Cosine Search"]
Search -->|Results| MainThread
end
Offline_Indexing -->|Artifacts Directory| Browser_Runtime
The system is split into two distinct phases. First, a Node.js CLI (`indexer-node`) uses `hnswlib-node` and `@xenova/transformers` to validate chunks, generate 384-dimensional embeddings, and construct an HNSW index, exporting binary artifacts. Second, a TypeScript web app (`web-app`) fetches these artifacts, caches them, and initializes a Web Worker. The worker loads the ONNX model via Transformers.js (preferring WebGPU) and handles search requests by computing query embeddings and running brute-force or HNSW-based cosine similarity against the cached vectors.
sequenceDiagram
participant User as User
participant UI as Main Thread (UI)
participant Worker as Search Worker
participant DB as IndexedDB
participant Model as Transformers.js (WebGPU)
Note over UI, DB: Initialization Phase
UI->>Worker: Post 'init' message with artifacts URL
Worker->>DB: Fetch artifacts (config, metadata, embeddings, index)
DB-->>Worker: Return cached artifacts
Worker->>Model: Load ONNX model
Model-->>Worker: Model ready
Worker-->>UI: Post 'ready' message
Note over UI, Model: Query Phase
User->>UI: Type query & click Search
UI->>Worker: Post 'search' message (query, topK, requestId)
Worker->>Model: Compute embedding for query
Model-->>Worker: Return query vector
Worker->>Worker: Perform cosine similarity search
Worker-->>UI: Post 'results' message (matches, latency)
UI->>User: Display search results
Use this pattern when building privacy-focused or offline-capable applications requiring semantic search over static datasets (like meeting transcripts or documentation). It eliminates latency and costs associated with hosted embedding APIs and vector databases. The architecture is model-agnostic, allowing you to swap ONNX sentence-transformer models without changing the core retrieval logic.