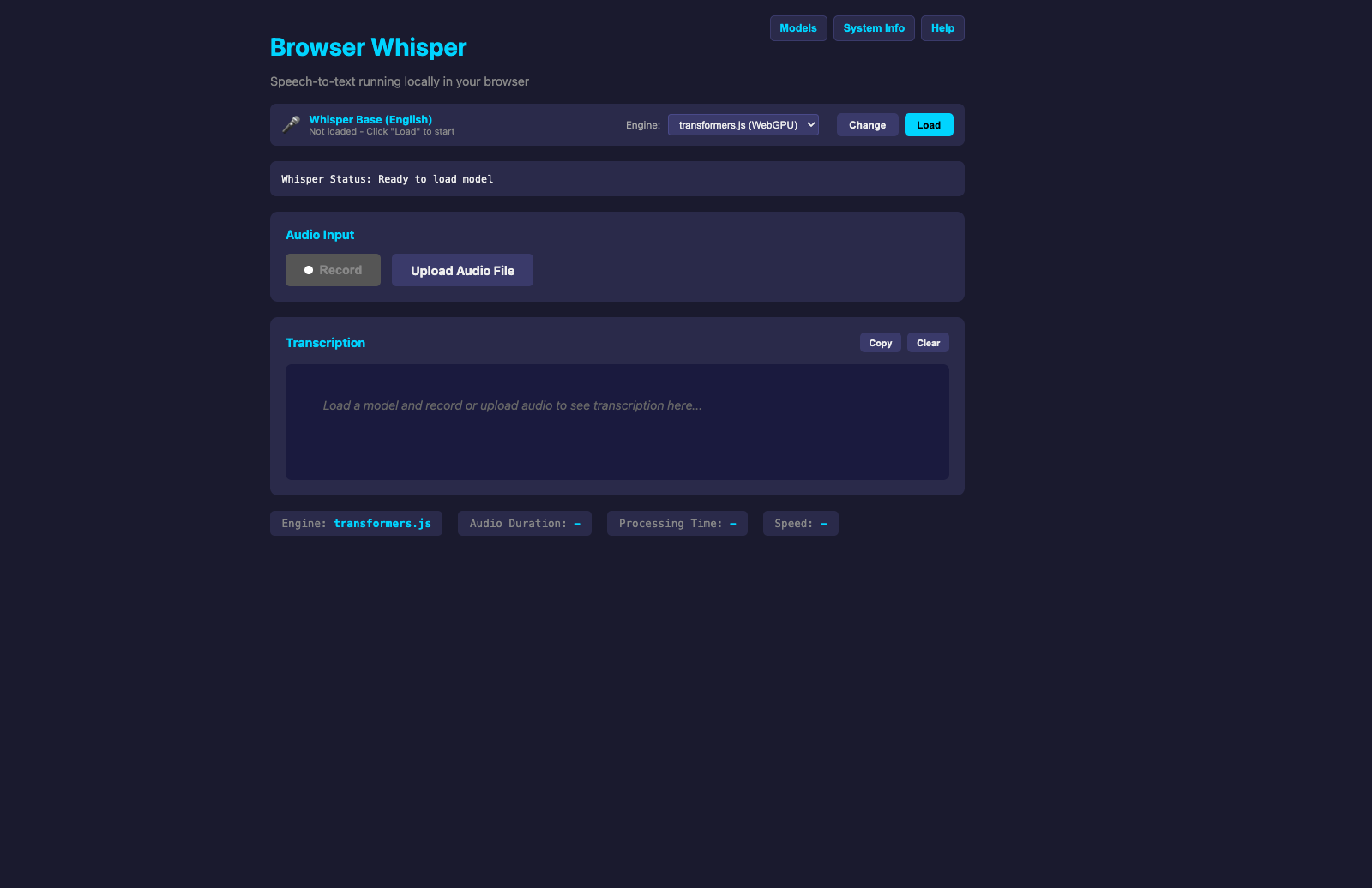
A client-side web application for private, offline speech-to-text transcription using OpenAI's Whisper models via WebGPU or WebAssembly.
https://github.com/davidbmar/browser-whisper-models-local-showcase · public · shipped
This project is a static HTML/JavaScript interface that enables users to perform speech-to-text transcription entirely within their browser. It leverages two distinct inference engines: transformers.js (utilizing ONNX Runtime and WebGPU for GPU acceleration) and whisper.cpp (compiled to WebAssembly for CPU optimization). The application supports 13+ Whisper model variants, ranging from Tiny to Large-v3, and handles audio input via file upload or direct microphone recording. All processing occurs locally, ensuring data privacy, with models cached in IndexedDB for subsequent use.
git clone https://github.com/davidbmar/browser-whisper-models-local-showcase.git cd browser-whisper-models-local-showcase python3 -m http.server 8080
flowchart TD
User[User] -->|Interacts| UI[HTML Interface]
UI -->|Selects Engine| EngineManager[Engine Manager]
EngineManager -->|Loads| TransformersJS[transformers.js<br/>ONNX Runtime + WebGPU]
EngineManager -->|Loads| WhisperCPP[whisper.cpp<br/>WASM + Web Worker]
UI -->|Provides Audio| AudioProc[Web Audio API]
AudioProc -->|Resampled PCM| TransformersJS
AudioProc -->|Resampled PCM| WhisperCPP
TransformersJS -->|Fetches| HF[Hugging Face Hub]
WhisperCPP -->|Uses Local| WASM_Binary[libmain.wasm]
HF -->|Caches| IDB[(IndexedDB)]
IDB -->|Serves| TransformersJS
TransformersJS -->|Returns Text| UI
WhisperCPP -->|Returns Text| UI
The application is built as a client-side single-page app using vanilla HTML, CSS, and JavaScript. It integrates Hugging Face's transformers.js library for WebGPU-based inference and the whisper.cpp C++ codebase compiled to WebAssembly (WASM) for CPU-based inference. It uses the Web Audio API for audio preprocessing and resampling, and relies on Service Workers (specifically coi-serviceworker) to enable Cross-Origin Isolation required for SharedArrayBuffer support in WASM threads.
sequenceDiagram
participant U as User
participant I as Index.html
participant E as Engine Logic
participant W as Web Worker/WASM
participant M as Model Cache (IDB)
U->>I: Select Model & Engine
I->>E: Initialize Engine
E->>M: Check for cached model
alt Model not cached
M-->>E: Miss
E->>E: Download from Hugging Face
E->>M: Store in IndexedDB
else Model cached
M-->>E: Hit
end
E->>W: Load Model into Memory
W-->>E: Ready
U->>I: Record/Upload Audio
I->>E: Process Audio Buffer
E->>W: Run Inference (PCM Data)
W->>W: Execute Whisper Forward Pass
W-->>E: Return Transcription Text
E-->>I: Update UI with Results
I-->>U: Display Transcript
Developers can use this repository as a reference implementation for integrating local LLMs or ASR models into web applications. It demonstrates how to manage large binary assets (models) in the browser, handle WebGPU vs. WASM fallbacks, and implement real-time audio processing pipelines without backend dependencies. It serves as a template for privacy-focused audio tools.
✓ all on main — nothing unmerged.