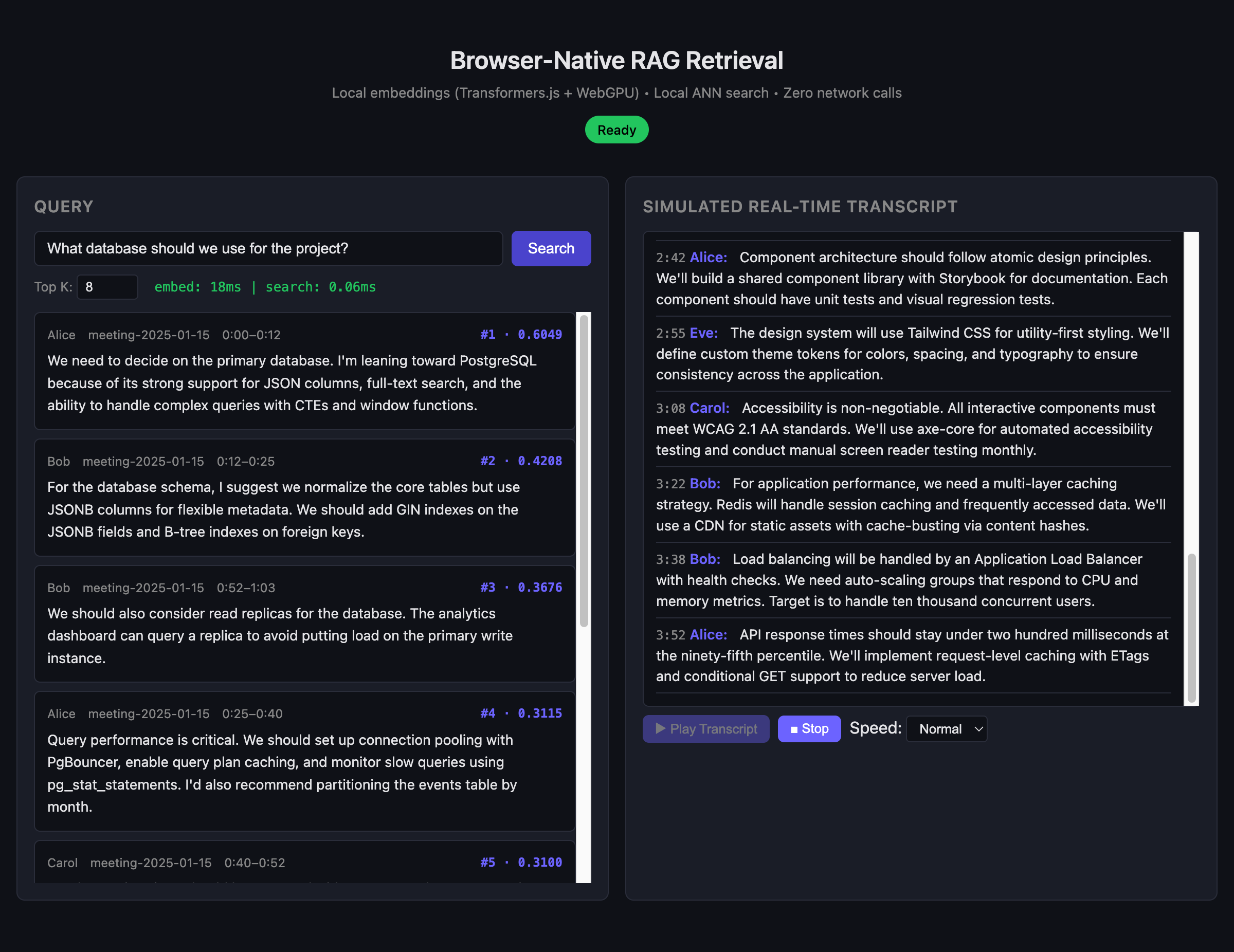
A fully local, WebGPU-accelerated RAG retrieval system that runs entirely in the browser with zero network calls at query time.
https://github.com/davidbmar/character-iris-kade-noir-cyberpunk-ai-browser-native-rag-llm-tts-stt · public · shipped
This project implements a production-shaped prototype for real-time transcription search where both embedding generation and vector search occur locally within the client's browser. It decouples retrieval from generation, allowing any downstream LLM to be paired with it. The system uses an offline Node.js CLI to index JSONL transcript chunks into HNSW artifacts, which are then loaded by a Vite-based web application. By leveraging Transformers.js and WebGPU, it achieves ~18ms query latency on modern hardware without sending data to external APIs.
git clone https://github.com/davidbmar/browser-RAG-retrieval-realtime-night-index-transformersjs-webgpu-web-app-vite-typescript.git cd browser-RAG-retrieval-realtime-night-index-transformersjs-webgpu-web-app-vite-typescript cd indexer-node && npm install cd ../web-app && npm install cd .. cd indexer-node npm run build-index -- --input ../data --out ../artifacts cd ../web-app mkdir -p public/artifacts cp ../artifacts/* public/artifacts/ npm run dev
flowchart TD
subgraph Offline_Indexing["Offline Indexing (Node.js)"]
JSONL["JSONL Chunks"] --> Validate["Validate & Normalize"]
Validate --> Embed["Embed via Transformers.js"]
Embed --> HNSW["Build HNSW Index"]
HNSW --> Artifacts["Export Artifacts\n(config, metadata, embeddings.bin, hnsw.index)"]
end
subgraph Browser_Runtime["Browser Runtime (Vite + TS)"]
MainThread["Main Thread\n(UI + Transcript Panel)"]
Worker["Web Worker\n(Search Engine)"]
Artifacts -->|Load & Cache| IndexedDB[("IndexedDB")]
IndexedDB --> Worker
MainThread -->|Query Text| Worker
Worker -->|Load Model| TransformersJS["Transformers.js\n(WebGPU/WASM)"]
TransformersJS -->|Query Embedding| Search["Cosine Similarity Search"]
Search -->|Results| MainThread
end
Offline_Indexing -->|Static Files| Browser_Runtime
The architecture is split into two distinct phases. First, an offline indexing pipeline (Node.js) uses `@xenova/transformers` to generate 384-dimensional sentence embeddings and `hnswlib-node` to build an Approximate Nearest Neighbor index. These artifacts (binary embeddings, index, and metadata) are exported as static files. Second, the browser runtime (Vite + TypeScript) loads these artifacts into IndexedDB. A dedicated Web Worker handles all heavy computation: it initializes the Transformers.js pipeline (preferring WebGPU, falling back to WASM), computes query embeddings on the fly, and performs cosine similarity search against the cached vectors, keeping the main UI thread responsive.
sequenceDiagram
participant User
participant UI as Main Thread
participant Worker as Search Worker
participant DB as IndexedDB
participant Model as Transformers.js
Note over UI, DB: Initialization Phase
UI->>Worker: Post 'init' message with artifacts URL
Worker->>DB: Fetch artifacts (config, metadata, embeddings)
DB-->>Worker: Return cached artifacts
Worker->>Model: Load embedding model (WebGPU/WASM)
Model-->>Worker: Model ready
Worker-->>UI: Post 'ready' status
Note over UI, Model: Query Phase
User->>UI: Type question & click Search
UI->>Worker: Post 'search' message (query, topK)
Worker->>Model: Compute query embedding
Model-->>Worker: Return Float32 vector
Worker->>Worker: Perform cosine similarity search
Worker-->>UI: Post 'results' (matches, latency)
UI->>User: Display ranked transcript chunks
Use this as a privacy-first retrieval layer for applications handling sensitive transcripts, such as legal depositions, medical records, or internal corporate meetings. It is ideal for scenarios where network latency or data sovereignty prevents the use of cloud-based vector databases. Developers can swap the underlying ONNX model to adjust for different languages or domain-specific terminology without changing the core retrieval logic.