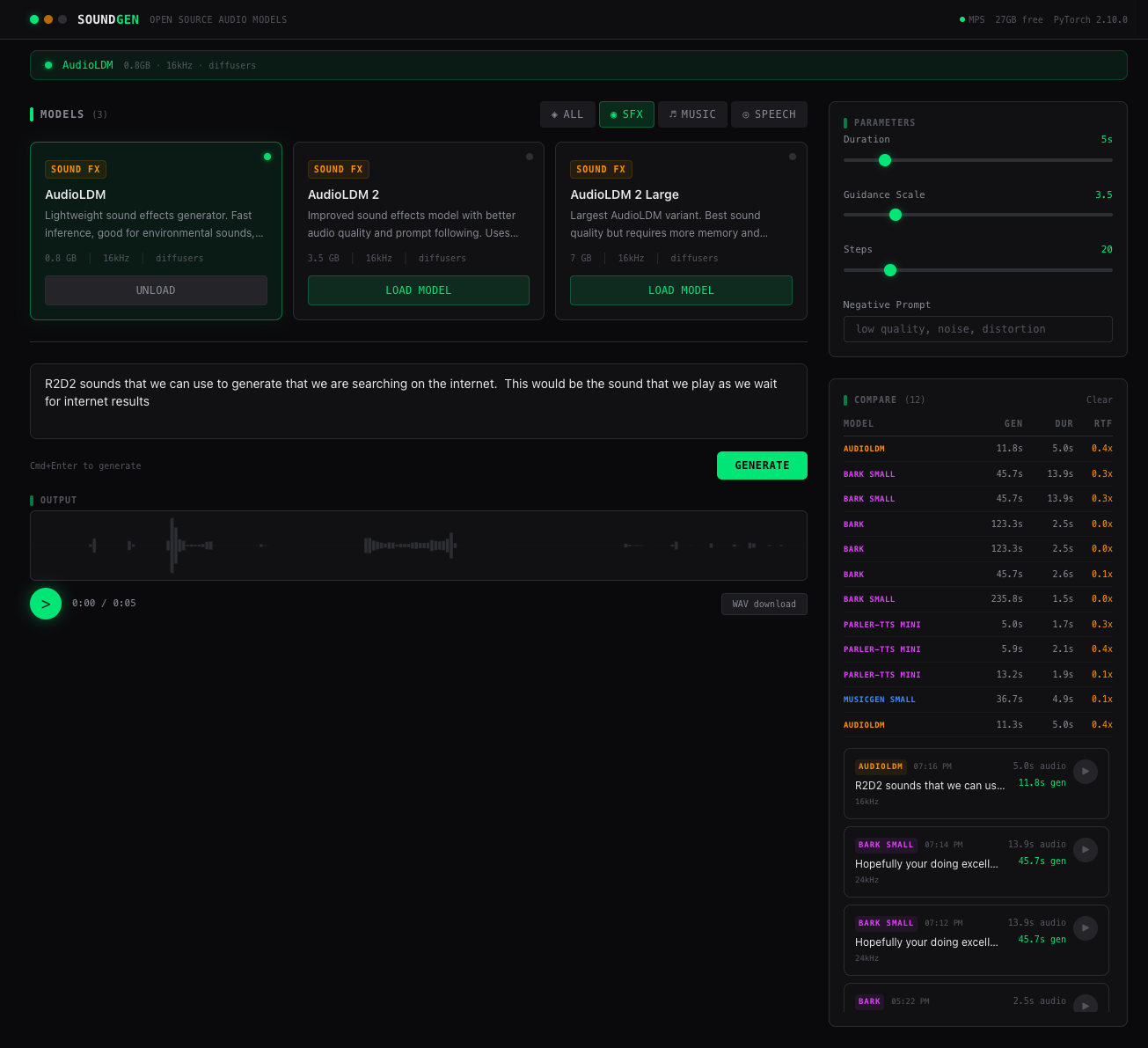
A local browser-based benchmarking suite for comparing nine open-source audio generation models with real-time progress streaming and Apple Silicon optimization.
https://github.com/davidbmar/opensource_sound_generator_llms · public · shipped
A full-stack application consisting of a React frontend and FastAPI backend that allows users to generate, compare, and benchmark sound effects, music, and speech models. It features real-time Server-Sent Events (SSE) for monitoring generation steps, an LRU cache for instant repeat results, and automated hardware detection to optimize for MPS (Apple Silicon), CUDA, or CPU.
git clone https://github.com/davidbmar/opensource_sound_generator_llms.git cd opensource_sound_generator_llms make install make start
flowchart TD
subgraph Client["Browser (React/Vite :5173)"]
UI["UI Components\n(Model Selector, Prompt Input)"]
Player["Audio Player & Waveform"]
Table["Compare Table"]
end
subgraph Server["Python Backend (FastAPI :8000)"]
API["API Routes\n(/api/generate-stream, /api/models)"]
MM["ModelManager\n(Asyncio Lock, One-at-a-time)"]
Cache["GenerationCache\n(LRU Store)"]
Gen["Generators\n(AudioLDM, MusicGen, Bark, etc.)"]
Utils["Audio Utils\n(Numpy to WAV)"]
end
UI -->|HTTP/SSE| API
API -->|Manage Lifecycle| MM
API -->|Check/Store| Cache
MM -->|Load/Unload| Gen
Gen -->|Raw Audio| Utils
Utils -->|WAV Bytes| Cache
Cache -->|WAV Bytes| API
API -->|SSE Progress| UI
API -->|WAV Binary| Player
Player -->|Display Data| Table
The backend uses FastAPI with PyTorch, Diffusers, and Transformers libraries to manage model loading and inference. It employs an asyncio lock to ensure only one model resides in memory at a time, using gc.collect() for cleanup. The frontend is built with React and Vite, consuming SSE streams for progress updates and fetching binary WAV data separately to avoid proxy limitations. Audio processing relies on NumPy and SoundFile for format conversion.
sequenceDiagram
participant User as Browser UI
participant API as FastAPI Endpoint
participant Manager as ModelManager
participant Model as Loaded Model
participant Cache as GenerationCache
User->>API: POST /api/generate-stream
API->>Cache: Check cache key
alt Cache Hit
Cache-->>API: Return cached WAV bytes
API-->>User: SSE: complete (instant)
else Cache Miss
API->>Manager: Acquire lock & get model
Manager->>Model: Ensure loaded (warm-up if needed)
loop Inference Steps
Model-->>API: Yield progress (step N/total)
API-->>User: SSE: progress event
end
Model-->>API: Return raw audio array
API->>Cache: Store WAV bytes
API-->>User: SSE: complete (audio_id)
User->>API: GET /api/audio/{id}
API-->>User: Binary WAV data
end
Use this project to evaluate the quality, speed, and resource consumption of different open-source audio models before integrating them into production pipelines. It serves as a reference implementation for handling large model swaps, streaming inference progress, and managing GPU/MPS memory constraints in local AI applications.