A zero-network, WebGPU-accelerated conversational AI with dual-LLM architecture, multi-lane RAG, and streaming TTS/STT running entirely in the browser.
https://github.com/davidbmar/speaker-generation-version-1 · public · shipped
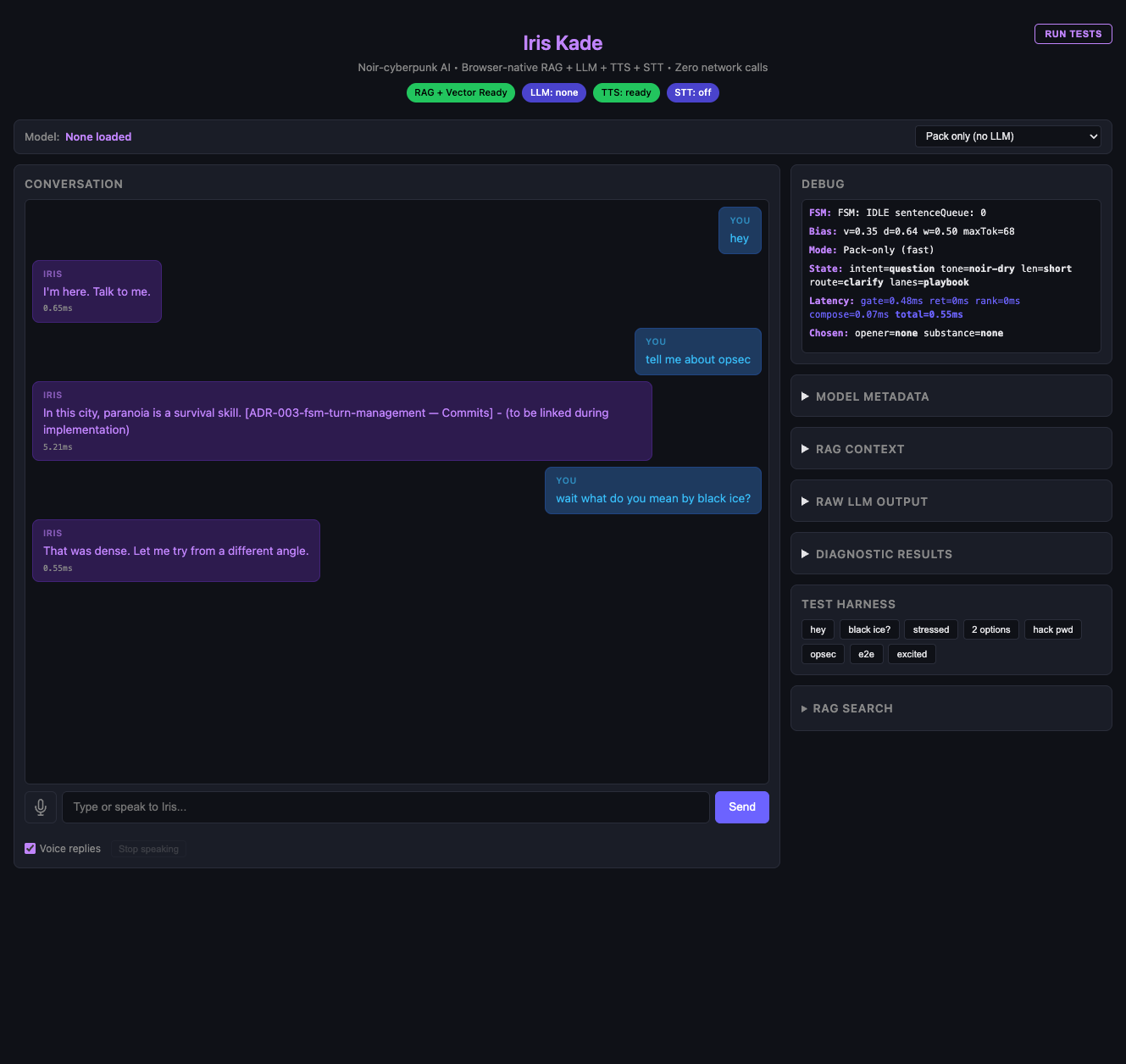
Iris Kade is a privacy-first, noir-cyberpunk themed conversational agent that operates 100% client-side. It eliminates cloud dependencies by leveraging WebGPU for local LLM inference, Web Speech API for voice interaction, and ONNX/WASM for text-to-speech. The system features a 4-state conversation FSM, adaptive response biasing, and a multi-lane Retrieval-Augmented Generation (RAG) pipeline that retrieves context from persona, playbook, knowledge, and lore vectors.
git clone https://github.com/davidbmar/speaker-generation-version-1.git cd speaker-generation-version-1/web-app npm install npm run dev
flowchart TD
User[User Input] -->|Voice/Text| STT[Web Speech API STT]
STT --> FSM[Conversation FSM]
FSM -->|IDLE to PROCESSING| Pipeline[RAG Pipeline]
Pipeline -->|Retrieve| VectorStore[(IndexedDB Artifacts)]
Pipeline -->|Rerank| Context[Context Composer]
Context --> LLM[Web-LLM Inference]
LLM -->|Stream Tokens| Buffer[Sentence Buffer]
Buffer --> TTS[vits-web TTS]
TTS --> Audio[Audio Output]
FSM -->|Interrupt| Buffer
FSM -->|Reset| Pipeline
Built with vanilla TypeScript and Vite, the application uses @mlc-ai/web-llm for GPU-accelerated model inference and @huggingface/transformers.js for embedding generation. Voice capabilities are handled by the Web Speech API (STT) and vits-web (TTS). State management relies on a finite state machine (IDLE/PROCESSING/SPEAKING/INTERRUPTED), while persistent storage for RAG artifacts utilizes IndexedDB. The build process includes custom scripts for indexing session data into JSONL packs for offline retrieval.
sequenceDiagram
participant U as User
participant FSM as Conversation FSM
participant RAG as RAG Pipeline
participant LLM as Web-LLM
participant TTS as vits-web Speaker
U->>FSM: Speak/Type Input
FSM->>FSM: Transition IDLE -> PROCESSING
FSM->>RAG: Request Context (Persona/Lore)
RAG->>RAG: Retrieve & Rerank Vectors
RAG-->>FSM: Composed Prompt
FSM->>LLM: Stream Generation Request
loop Token Streaming
LLM-->>FSM: Return Token
FSM->>TTS: Enqueue Sentence
end
TTS->>U: Play Audio Stream
alt User Interrupts
U->>FSM: Interrupt Signal
FSM->>LLM: Abort Generation
FSM->>TTS: Clear Buffer
FSM->>FSM: Transition to INTERRUPTED
end
Deploy as a static web application requiring no backend infrastructure. Ideal for secure environments where data sovereignty is critical, educational tools for teaching opsec/privacy, or offline-capable interactive characters. The modular architecture allows swapping LLMs (80MB–5GB) and TTS engines without altering core logic.