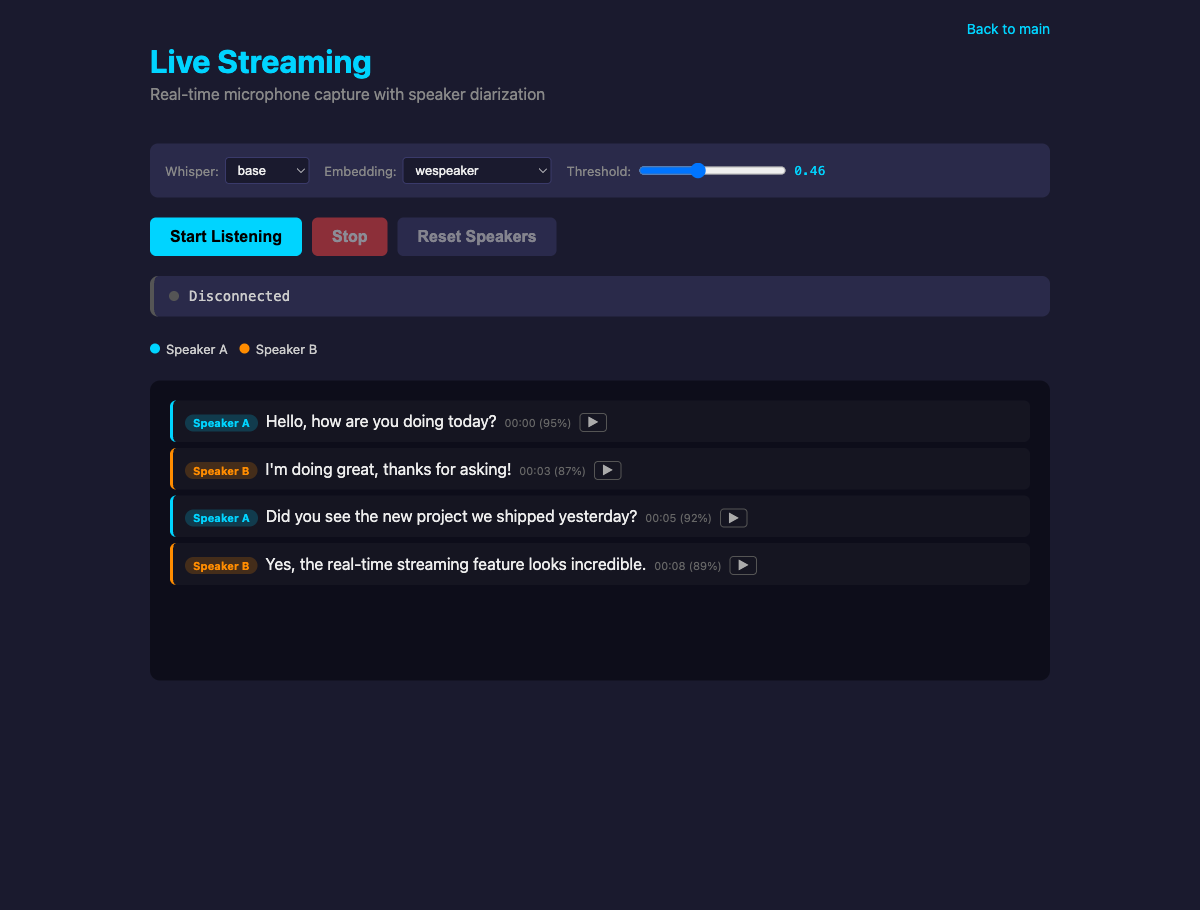
Real-time speaker diarization and voice fingerprinting system using multiple embedding models.
https://github.com/davidbmar/voice-print · public · shipped
A full-stack application that identifies who is speaking in live audio streams or recorded files. It combines browser-native Whisper transcription (via WebGPU/WASM) with a Python backend for speaker embedding extraction and incremental clustering, allowing users to benchmark different AI models side-by-side without sending audio to external cloud APIs.
git clone https://github.com/davidbmar/voice-print.git cd voice-print python3 -m venv .venv source .venv/bin/activate pip install -r backend/requirements.txt bash scripts/serve.sh
flowchart TD
subgraph Client [Browser]
Mic[Microphone Input]
AW[AudioWorklet]
UI[Frontend UI]
Whisper[Whisper WASM/WebGPU]
end
subgraph Server [FastAPI Backend]
WS[WebSocket Handler]
RB[Ring Buffer 30s]
SBD[Sentence Boundary Detection]
Emb[Embedding Extractor]
Cluster[Speaker Clusterer]
ModelReg[Model Registry]
end
Mic -->|16kHz PCM| AW
AW -->|Binary Frames| WS
WS --> RB
RB --> SBD
SBD -->|Audio Segment| Emb
Emb -->|Load Model| ModelReg
Emb -->|Vector| Cluster
Cluster -->|Speaker ID| WS
WS -->|JSON Label| UI
UI -->|Click Replay| Whisper
The frontend uses vanilla HTML/JS with AudioWorklets for low-latency microphone capture and WebSocket binary frames for streaming. The backend is a FastAPI server managing a ring buffer, Faster Whisper for transcription, and a registry of five speaker embedding models (WeSpeaker, CAM++, Resemblyzer, SpeechBrain ECAPA, Pyannote). Clustering is performed incrementally using cosine similarity against speaker centroids.
sequenceDiagram
participant Browser
participant AudioWorklet
participant FastAPI
participant RingBuffer
participant Embedder
participant Clusterer
Browser->>AudioWorklet: Start Mic Capture
loop Every 100ms
AudioWorklet->>FastAPI: Send Binary PCM Chunk (WS)
FastAPI->>RingBuffer: Append Audio Data
RingBuffer->>FastAPI: Check Sentence Boundary
alt Sentence Complete
FastAPI->>Embedder: Extract Audio Segment
Embedder->>Embedder: Compute Fbank/Features
Embedder->>Embedder: Run ONNX/PyTorch Model
Embedder->>Clusterer: Return Embedding Vector
Clusterer->>Clusterer: Cosine Similarity Check
Clusterer->>FastAPI: Assign Speaker ID
FastAPI->>Browser: JSON {text, speaker_id}
end
end
Use this project as a reference for building real-time audio analysis pipelines. It demonstrates how to handle binary WebSocket streams, implement lazy-loading model registries in Python, perform incremental clustering without pre-defined speaker counts, and run heavy inference tasks (Whisper) entirely in the browser to reduce server load.
✓ all on main — nothing unmerged.